
Bài viết này sẽ hướng dẫn bạn cách xác định nhanh nguyên nhân và khắc phục hoàn toàn lỗi IndentationError: unindent does not match any outer indentation level trong Python. Thông qua việc phân tích cách trình biên dịch xử lý khoảng trắng, bạn sẽ nắm được quy chuẩn định dạng code chuyên nghiệp, tránh lặp lại sự cố này trong các dự án thực tế.
Bạn xem thêm:
- SyntaxError Missing Colon: 2 Cách Sửa Lỗi Thiếu Dấu ‘:’ Python
- Đếm Số Lượng Ký Tự, Số Và Ký Tự Đặc Biệt Trong Chuỗi Python
- Hướng dẫn đếm số ký tự trong chuỗi Python (Kèm code chuẩn)
💡 Trả lời nhanh: Lỗi này xuất hiện khi bạn lùi lề (unindent) một dòng lệnh nhưng số lượng khoảng trắng hoặc tab ở dòng đó không khớp chính xác với bất kỳ cấp độ thụt lề nào của các khối lệnh (block) bao bọc nó trước đó. Cách sửa nhanh nhất là bật chế độ hiển thị ký tự khoảng trắng (Render Whitespace) trên IDE để tìm ra dòng đang bị trộn lẫn giữa Tab và Space, sau đó chuyển đổi toàn bộ về chuẩn 4 spaces.
Đề bài
Input: Một đoạn mã nguồn Python chứa cấu trúc điều khiển (vòng lặp, rẽ nhánh) hoặc định nghĩa hàm, nhưng khi chạy lại báo lỗi cú pháp liên quan đến lề. Ví dụ, một hàm kiểm tra số dương bị báo lỗi ngay tại dòng lệnh print("Done") ở cuối khối lệnh.
Output: Mã nguồn được định dạng lại chuẩn xác theo PEP 8, chạy thành công không văng lỗi, đồng thời cấu hình được môi trường phát triển (IDE) để tự động ngăn chặn việc gõ sai chuẩn tab/space trong tương lai.
Ràng buộc: Cần giải thích rõ bản chất cách Python 3 phân tích từ vựng (lexical analysis) đối với khoảng trắng. Giải pháp đưa ra phải phù hợp với sinh viên năm 2 đã nắm vững cú pháp cơ bản nhưng chưa có thói quen làm việc chặt chẽ với quy chuẩn của các dự án lớn.
Phân tích
Lỗi IndentationError: unindent does not match any outer indentation level trong Python 3 xảy ra khi một dòng code được lùi ra ngoài (unindent) nhưng số lượng khoảng trắng (spaces hoặc tab) lại không khớp chính xác với cấp độ thụt lề của bất kỳ khối lệnh nào được khởi tạo trước đó. Khác với các ngôn ngữ như C++ hay Java dùng cặp ngoặc nhọn {} để xác định phạm vi khối lệnh, Python phụ thuộc hoàn toàn vào thụt lề (indentation).
Trình biên dịch của Python sử dụng một cấu trúc dữ liệu dạng ngăn xếp (stack) để theo dõi các cấp độ thụt lề. Khi đọc mã nguồn từ trên xuống dưới, cứ mỗi lần gặp một mức lề mới lớn hơn mức lề hiện tại, Python sẽ đẩy (push) giá trị đó vào ngăn xếp. Khi gặp một dòng có lề nhỏ hơn, nó bắt đầu lấy (pop) các giá trị ra khỏi ngăn xếp cho đến khi tìm thấy một giá trị khớp chính xác với lề của dòng hiện tại. Nếu quá trình pop này kết thúc mà không có con số nào trùng khớp, trình biên dịch sẽ lập tức báo lỗi “unindent does not match”.
📌 Góc nhìn thực tế: Trong thực tế, sinh viên thường xuyên gặp lỗi này khi sao chép code từ StackOverflow hoặc ChatGPT rồi dán vào một file code đang viết dở. Trình duyệt web thường sử dụng khoảng trắng (spaces) để hiển thị code, trong khi bạn có thể đang dùng phím Tab trong trình soạn thảo của mình. Sự mâu thuẫn này tạo ra lỗi mix tab space python error cực kỳ phổ biến.
Giả định
Bài viết này giả định bạn đang sử dụng một trình soạn thảo mã nguồn chuyên dụng (như VS Code hoặc PyCharm) chứ không phải các công cụ soạn thảo văn bản thông thường như Notepad. Việc dùng IDE chuyên dụng là bắt buộc đối với sinh viên CNTT để quản lý code hiệu quả.
Từ sự phân tích trên, chúng ta có hai hướng tiếp cận để xử lý: một là chẩn đoán và sửa trực tiếp dòng code bị hỏng (phù hợp khi chỉ sai một vài chỗ), hai là cấu hình IDE tự động hóa việc đồng bộ khoảng trắng (giải pháp cốt lõi, lâu dài).
Cách giải 1: Chẩn đoán và sửa trực tiếp (Thủ công)
Cách tiếp cận thủ công giúp bạn hiểu chính xác bản chất lỗi thụt lề không khớp python bằng cách yêu cầu bạn tự tay xác định ký tự ẩn đang gây ra sự cố.
Chẩn đoán lỗi thụt lề
Bạn không thể phân biệt được Tab và Space nếu chỉ nhìn bằng mắt thường trên màn hình soạn thảo trắng. Ký tự Tab có độ rộng linh hoạt, có thể hiển thị tương đương 4 spaces hoặc 8 spaces tùy theo cấu hình của IDE. Do đó, dòng có 1 Tab và dòng có 4 Spaces có thể nằm thẳng hàng nhau một cách hoàn hảo, lừa thị giác của bạn nhưng lại khiến trình biên dịch Python 3 “nổi điên”.
Để chẩn đoán, bạn cần bật tính năng hiển thị ký tự khoảng trắng (Render Whitespace). Trên VS Code, bạn có thể vào View > Appearance > Render Whitespace, hoặc mở Settings (Ctrl + ,) và tìm kiếm renderWhitespace, chuyển thành all. Khi đó, không gian trống sẽ hiện ra dưới dạng các dấu chấm nhỏ . (đại diện cho Space) và dấu mũi tên → (đại diện cho Tab).
Code gốc chứa lỗi
Dưới đây là một đoạn mã minh họa việc mix tab space gây lỗi. Dòng số 6 đang bị lỗi.
def process_data(data):
for item in data:
if item > 0:
print("Valid")
print("Done") # Dòng này lùi vào 3 spaces, không khớp với 4 spaces của for, cũng không khớp 0 của def
Trong đoạn code trên, khối for ở cấp độ 4 spaces. Khối if ở cấp độ 8 spaces. Dòng print("Done") được tác giả định lùi về cấp độ của for nhưng vô tình chỉ gõ 3 spaces (hoặc dùng một hệ thống mix tab/space lộn xộn). Khi Python lấy dần các mức lề từ ngăn xếp (8, 4, 0) để so sánh với mức lề hiện hành (3), nó không tìm thấy số 3 nào trong ngăn xếp. Ngay lập tức, lỗi indentationerror unindent được kích hoạt.
Code đã sửa chuẩn hóa
Để sửa lỗi, bạn phải căn chỉnh lại số lượng khoảng trắng của dòng bị lỗi sao cho khớp tuyệt đối với một trong các cấp độ lề đã mở trước đó.
def process_data(data):
for item in data:
if item > 0:
print("Valid")
print("Done") # Đã sửa: lùi đúng 4 spaces, khớp với cấp độ của vòng lặp for
Giải thích sâu & Cải thiện
Việc sửa lại thành 4 spaces đúng chuẩn không chỉ giúp mã nguồn chạy được mà còn tuân thủ nguyên tắc cốt lõi của tài liệu Lexical Analysis của Python. Python 3 đã chính thức cấm việc pha trộn giữa Tab và Space. Thay vì chỉ cảnh báo như Python 2, Python 3 sẽ từ chối chạy đoạn code có chứa lỗi này. Để code luôn sạch, bạn hãy tập thói quen bấm phím Tab, nhưng cấu hình trình soạn thảo tự động chuyển phím Tab đó thành 4 dấu cách.
Mặc dù việc sửa thủ công này rất tốt để hiểu bài, nhưng sẽ ra sao nếu bạn mở một tệp dự án chứa hàng nghìn dòng code đều mắc lỗi tương tự? Bạn không thể ngồi gõ lại lề cho từng dòng. Đó là lúc chúng ta cần đến Cách 2.
Cách giải 2: Cấu hình IDE xử lý triệt để (Tự động hóa)
Khác với Cách 1 tập trung vào sửa từng dòng code, cách này thiết lập một hàng rào bảo vệ ngay từ môi trường soạn thảo, tự động dọn dẹp và chuẩn hóa lỗi python tab vs space cho toàn bộ file chỉ bằng vài cú click.
Ý tưởng cốt lõi
Khác với Cách 1 ở chỗ, chúng ta không cần quan tâm dòng nào đang bị lỗi. Chúng ta sẽ sử dụng công cụ Format Document được tích hợp sẵn trong các IDE hiện đại để quét toàn bộ file, tìm tất cả các ký tự Tab và thay thế chúng hoàn toàn bằng các ký tự Space tương ứng. Sau đó, chúng ta lưu cấu hình này lại thông qua file .editorconfig hoặc cấu hình Workspace để đảm bảo mã code luôn đồng nhất.
Các bước triển khai
Trên Visual Studio Code (VS Code), quá trình này chỉ mất vài giây. Đầu tiên, hãy nhìn xuống thanh trạng thái (Status Bar) ở dưới cùng bên phải cửa sổ VS Code, bạn sẽ thấy một mục ghi là “Spaces: 4” hoặc “Tab Size: 4”. Bạn hãy click vào mục đó.
Một menu thả xuống (Command Palette) sẽ xuất hiện. Lúc này, bạn chọn lệnh Convert Indentation to Spaces. VS Code sẽ ngay lập tức rà soát toàn bộ file và biến đổi mọi ký tự Tab thành 4 dấu cách (Space). Tiếp theo, để phòng ngừa, bạn hãy nhấn tổ hợp phím Shift + Alt + F để định dạng lại toàn bộ mã nguồn theo chuẩn PEP 8 (nếu bạn đã cài đặt các linter/formatter như Pylint, Black hoặc Autopep8).
Với PyCharm, bạn chỉ cần quét chọn toàn bộ code bằng Ctrl + A, sau đó trên thanh menu chọn Edit > Convert Indents > To Spaces. PyCharm là môi trường chuyên biệt cho Python nên nó xử lý vấn đề thụt lề cực kỳ thông minh.
Minh họa kết quả
Dù đoạn code của bạn có thụt lề hỗn loạn đến đâu, sau khi chạy lệnh tự động hóa, cấu trúc sẽ trở nên rõ ràng và đồng nhất.
Khi nào nên dùng Cách 2?
Bạn nên áp dụng cấu hình tự động này ngay từ ngày đầu tiên tạo lập dự án. Đặc biệt, thao tác Convert Indentation to Spaces là thao tác bắt buộc đầu tiên mỗi khi bạn sao chép mã nguồn từ trên mạng, clone dự án từ GitHub của người khác, hoặc làm việc nhóm với những người có thói quen sử dụng trình soạn thảo khác nhau.
Đánh giá
-
Ưu điểm: Nhanh chóng, chính xác tuyệt đối, loại bỏ triệt để hoàn toàn lỗi trên toàn bộ file code lớn. Tiết kiệm công sức rà soát thủ công.
-
Nhược điểm: Đôi khi việc tự động định dạng lại toàn bộ file có thể tạo ra một commit lớn trong Git (những dòng không lỗi cũng bị format lại, làm dơ lịch sử phiên bản).
-
Độ phức tạp:
O(1) thời giantừ phía người dùng /O(N) thời gianxử lý của IDE với N là độ dài file.
Để bạn dễ dàng hệ thống hóa kiến thức, dưới đây là bảng đối chiếu trực quan hai phương pháp này.
So sánh nhanh 2 cách
Bảng này giúp bạn quyết định nên dùng cách nào để fix lỗi indentationerror unindent mà không cần đọc lại toàn bài.
| Tiêu chí | Cách 1: Chẩn đoán và sửa trực tiếp (Thủ công) | Cách 2: Cấu hình IDE xử lý triệt để (Tự động hóa) |
| Ý tưởng cốt lõi | Bật hiện khoảng trắng, tìm dòng lỗi và gõ lại lề cho đúng chuẩn. | Dùng tính năng Convert Indent của IDE để thay thế toàn bộ file thành chuẩn Space. |
| Độ phức tạp | O(N) thời gian (phải tự dò tìm dòng lỗi) | O(1) thao tác (IDE lo toàn bộ) |
| Dễ đọc / dễ hiểu | ★★★★★ (Dễ hiểu bản chất) | ★★★☆☆ (Hiểu công cụ, ít hiểu logic dưới lề) |
| Hiệu năng | ★★☆☆☆ (Rất chậm nếu file code lớn) | ★★★★★ (Sửa hàng vạn dòng trong 1 giây) |
| Phù hợp khi | Code ngắn, muốn hiểu chính xác dòng code nào đang gõ sai, hoặc đang luyện tập sửa lỗi cơ bản. | Code dài, copy code từ bên ngoài vào, làm việc nhóm hoặc setup dự án chuẩn chuyên nghiệp. |
| Không phù hợp khi | File quá dài, code nhận từ nhiều nguồn có chuẩn format lộn xộn. | Môi trường không có IDE xịn, chỉ dùng vi/nano qua terminal SSH. |
Khi đã hiểu bản chất và cấu hình tốt IDE, việc viết một đoạn mã Python sạch và đúng chuẩn trở nên rất dễ dàng.
Code Python đầy đủ
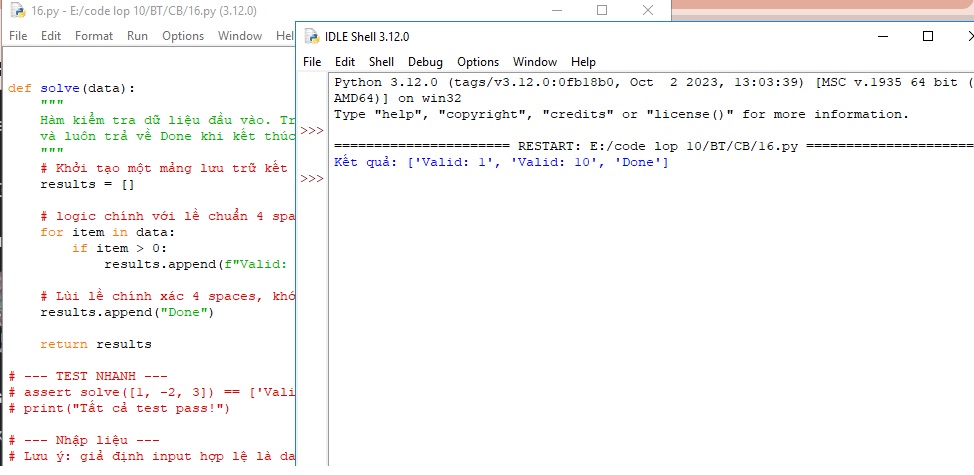
Cách 1 — Chẩn đoán và sửa trực tiếp (Thủ công):
# Tên biến nhất quán với phần minh họa tay
def solve(data):
"""
Hàm kiểm tra dữ liệu đầu vào. Trả về thông báo Valid cho số dương,
và luôn trả về Done khi kết thúc duyệt.
"""
# Khởi tạo một mảng lưu trữ kết quả để dễ test
results = []
# logic chính với lề chuẩn 4 spaces liên tiếp
for item in data:
if item > 0:
results.append(f"Valid: {item}")
# Lùi lề chính xác 4 spaces, khớp với khối lệnh for
results.append("Done")
return results
# --- TEST NHANH ---
# assert solve([1, -2, 3]) == ['Valid: 1', 'Valid: 3', 'Done']
# print("Tất cả test pass!")
# --- Nhập liệu ---
# Lưu ý: giả định input hợp lệ là danh sách số nguyên (MUC_DO = trung cấp)
try:
user_input = [1, -5, 10]
print("Kết quả:", solve(user_input))
except Exception as e:
print("Đã xảy ra lỗi hệ thống:", e)
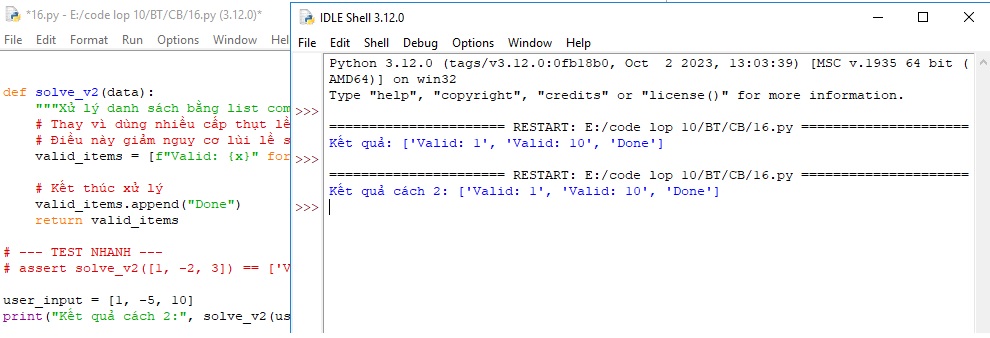
Cách 2 — Cấu hình IDE xử lý triệt để (Tự động hóa):
# Điểm khác với Cách 1: Đoạn code này đại diện cho một file đã được
# Auto-Format. Khối lượng code dày đặc hơn nhưng thụt lề vẫn chính xác 100%.
def solve_v2(data):
"""Xử lý danh sách bằng list comprehension để giảm thiểu thụt lề phức tạp."""
# Thay vì dùng nhiều cấp thụt lề (for rồi đến if), ta dùng cú pháp nén
# Điều này giảm nguy cơ lùi lề sai cấp.
valid_items = [f"Valid: {x}" for x in data if x > 0]
# Kết thúc xử lý
valid_items.append("Done")
return valid_items
# --- TEST NHANH ---
# assert solve_v2([1, -2, 3]) == ['Valid: 1', 'Valid: 3', 'Done']
user_input = [1, -5, 10]
print("Kết quả cách 2:", solve_v2(user_input))Dưới đây là một số ví dụ minh họa về các tình huống chạy thử để bạn đối chiếu.
Ví dụ chạy thử
| STT | Input data | Output | Giải thích |
| 1 | [1, 2] |
['Valid: 1', 'Valid: 2', 'Done'] |
Luồng thông thường. Tất cả số dương được nhận diện và vòng lặp kết thúc thành công. |
| 2 | [-1, -2] |
['Done'] |
Vòng for chạy nhưng điều kiện if item > 0 sai. Lệnh lùi lề báo “Done” hoạt động bình thường, chứng tỏ khối code thụt lề đúng. |
| 3 | [] (List rỗng) |
['Done'] |
Edge case: Khối for không được thực thi lần nào. Tuy nhiên dòng lùi lề print("Done") (hoặc append) vẫn chạy, hệ thống lề hoàn toàn hợp lệ. |
Trong thực tế lập trình, việc nắm vững cấu trúc chuẩn trên lý thuyết là chưa đủ. Bạn cần phải biết cách đối diện với các thông báo lỗi khi chúng phát sinh.
Lỗi thường gặp
Lỗi 1: Mix tab và space vô tình khi copy từ web
Hiện tượng mix tab space python error xảy ra phổ biến nhất với việc copy. Output văng lỗi TabError: inconsistent use of tabs and spaces in indentation hoặc báo unindent không khớp.
Nguyên nhân sâu xa là do mã nguồn gốc trên web (như GitHub hay StackOverflow) được định dạng bằng spaces, trong khi trình soạn thảo của bạn đang thiết lập thụt lề bằng Tab. Khi bạn dán code và tự gõ thêm dòng mới bằng phím Tab, hai hệ thống ký tự này xung đột với nhau. Kể từ Python 3, sự pha trộn này bị cấm hoàn toàn.
Code sai:
# Dòng def dùng không gian (spaces), dòng if dùng tab
def check():
if True: # Lùi bằng 4 spaces
print("OK") # Lùi bằng 1 Tab (mắt thường thấy giống 4 spaces)
Code đúng:
# Bôi đen toàn bộ và nhấn Format Document trên IDE
def check():
if True:
print("OK") # Đã quy chuẩn toàn bộ thành 4 spaces
Lỗi 2: Dùng Notepad hoặc trình soạn thảo không chuyên
Hiện tượng: Output báo lỗi cấu trúc lề bất hợp lý dù nhìn bằng mắt thường mã nguồn vẫn thẳng tắp, thụt lề rất đẹp và ngay ngắn.
Nguyên nhân vì các trình soạn thảo thô sơ như Notepad của Windows không có cơ chế quản lý và kiểm tra lề (linter). Bạn có thể gõ 3 dấu cách ở một dòng, và 5 dấu cách ở dòng dưới. Chữ vẫn hiện thẳng hàng do font chữ hệ thống không phải dạng monospaced, khiến bộ đếm ngăn xếp (indentation stack) của trình biên dịch Python bị sai lệch, không tìm thấy mức lề nào khớp nhau.
Code sai:
if n > 0:
print("Positive") # Lùi 3 spaces (font chữ thường làm nó trông có vẻ cân đối)
Code đúng:
if n > 0:
print("Positive") # Dùng IDE với font Consolas, lùi đúng 4 spaces
Lỗi 3: Lùi lề sai cấp cấu trúc (Logical Indentation Error)
Hiện tượng: Output văng lỗi IndentationError: unindent does not match... tại một vị trí mà bạn tin rằng mình đã gõ lề đúng.
Nguyên nhân là do việc bạn lùi lề (unindent) về một khoảng trắng không tương ứng với bất kỳ cấp độ block mẹ nào. Ví dụ, hàm ở lề 0 spaces, vòng for lề 4 spaces, if lề 8 spaces. Bạn lùi dòng lệnh tiếp theo xuống 6 spaces. Trình biên dịch hiểu bạn muốn kết thúc khối if, nhưng mức 6 spaces không khớp mức 4 của for hay mức 0 của hàm.
Code sai:
def loop():
for i in range(2):
if i > 0:
pass
print(i) # Lùi 6 spaces, lơ lửng giữa for(4) và if(8)
Code đúng:
def loop():
for i in range(2):
if i > 0:
pass
print("Done") # Lùi đúng 4 spaces, khớp với vòng for
Lỗi 4: Lỗi dòng trống (Empty line with whitespaces)
Hiện tượng: Báo lỗi thụt lề không khớp python ngay tại một dòng trống không hề chứa bất kỳ dòng code thực thi nào.
Nguyên nhân là do trình biên dịch Python 3 phân tích chặt chẽ cả những dòng trống (blank lines). Nếu một dòng trống được lùi lề thụt vào không đồng nhất (chứa một vài khoảng trắng ngẫu nhiên do bạn lỡ gõ phím Space), dù không có code, hệ thống phân tích từ vựng (lexer) đôi khi vẫn tính đó là một mức lề bất hợp lệ khi phân giải chuỗi khối lệnh tiếp theo.
Code sai:
def func():
print("A")
# Dòng comment này lùi sai (chỉ 2 spaces)
print("B")
Code đúng:
def func():
print("A")
# Xóa khoảng trắng thừa, căn đúng 4 spaces cho comment
print("B")
Lỗi 5: Lỗi thụt lề khi dùng cặp dấu ngoặc đa dòng (Multiline constructs)
Hiện tượng: Báo lỗi định dạng lề ngay sau khi đóng ngoặc của một list, dict hoặc lệnh gọi hàm kéo dài qua nhiều dòng.
Nguyên nhân: Khi bạn mở ngoặc [, { hoặc ( và tách các phần tử ra nhiều dòng, trình biên dịch cho phép các dòng bên trong lùi lề tự do để dễ nhìn. Tuy nhiên, nếu bạn đóng ngoặc không thẳng hàng với cấu trúc ban đầu, lệnh tiếp theo sau đó có thể bị hiểu lầm về cấp độ thụt lề, dẫn đến việc thụt lề bị đẩy ra xa hoặc kéo lại gần sai khối lệnh cơ sở.
Code sai:
my_list = [
1, 2, 3
] # Lùi 2 spaces, bất đối xứng với đầu list
print("OK")
Code đúng:
my_list = [
1, 2, 3
] # Đưa dấu ngoặc thẳng hàng với biến khởi tạo
print("OK")
Những lỗi trên là minh chứng rõ ràng nhất cho thấy sự chặt chẽ của Python so với các ngôn ngữ khác. Phần tiếp theo sẽ giải đáp nhanh các thắc mắc cốt lõi.
Câu hỏi thường gặp
Lỗi indentationerror unindent does not match any outer indentation level là gì?
Lỗi IndentationError: unindent does not match any outer indentation level là một lỗi cú pháp đặc trưng của trình biên dịch Python. Nó xảy ra khi bạn kết thúc một khối mã (bằng cách lùi lề sang trái) nhưng số lượng khoảng trắng tại dòng mới không khớp chính xác với số lượng khoảng trắng của bất kỳ khối lệnh nào được khai báo trước đó. Python dựa vào lề để xác định cấu trúc thay vì dùng ngoặc {}.
Thuật ngữ lỗi thụt lề không khớp python thực chất mô tả điều gì trong bộ biên dịch?
Thuật ngữ “lỗi thụt lề không khớp python” mô tả việc bộ phận phân tích từ vựng (lexer) của Python bị mất phương hướng khi theo dõi ngăn xếp thụt lề. Khi lexer phân giải từ trên xuống, nó lưu các cấp độ lề (ví dụ: 0, 4, 8) vào một mảng (stack). Khi gặp một dòng lùi ra mức lề lạ (ví dụ: 3), nó không tìm thấy số 3 trong stack để đóng đúng số lượng block tương ứng, do đó phát ra lỗi không khớp lề.
Làm thế nào để tự động sửa lỗi mix tab space python error?
Để tự động sửa lỗi mix tab space python error nhanh nhất, bạn cần sử dụng một IDE hiện đại như VS Code hoặc PyCharm. Trên VS Code, bạn mở Command Palette (Ctrl+Shift+P), gõ và chọn lệnh Convert Indentation to Spaces. Thao tác này sẽ rà soát toàn bộ file và biến đổi mọi ký tự Tab đang ẩn giấu trở thành chuẩn 4 dấu cách, đồng bộ hóa hoàn toàn cấp độ lề của file code.
Làm cách nào để cấu hình Python luôn dùng chuẩn 4 dấu cách để tránh lỗi thụt lề?
Bạn có thể ép chuẩn định dạng bằng cách thiết lập tệp .editorconfig ở thư mục gốc của dự án. Trong tệp này, thêm đoạn cấu hình [*.py] với thông số indent_style = space và indent_size = 4. Các trình soạn thảo mã nguồn hiện đại sẽ tự động đọc file này và cấu hình phím Tab trên bàn phím của bạn hoạt động như 4 phím Space, tuân thủ đúng PEP 8.
Nên dùng tính năng Convert Indent hay xóa sửa lề thủ công để chữa indentationerror unindent?
Bạn nên dùng chức năng Convert Indent tự động của IDE nếu file code dài hàng trăm dòng, hoặc bạn vừa sao chép đoạn mã đó từ StackOverflow. Việc xử lý tự động tiết kiệm hàng giờ dò tìm bằng mắt. Chỉ nên sửa thủ công khi dự án rất nhỏ (chưa tới 50 dòng) và bạn muốn tận dụng cơ hội rà soát lại logic phân cấp rẽ nhánh, vòng lặp của chính mình xem đã tối ưu hay chưa.
Sự khác biệt cơ bản giữa lỗi unindent does not match và lỗi unexpected indent là gì?
Lỗi unexpected indent xảy ra khi mã nguồn tự nhiên tiến lùi vào trong (thêm lề thụt vào) một cách bất hợp lý mà không có câu lệnh mở block (như if:, for:, def:) nào đứng trước nó. Ngược lại, unindent does not match xảy ra ở chiều ngược lại, khi bạn đã lùi lề để kết thúc một block, nhưng khoảng cách lùi ra ngoài lại lỡ dở, không khớp về bằng với lề của cấp độ mẹ đang chờ.
Tại sao mã code lỗi thụt lề không khớp python chạy bình thường trên máy cũ nhưng sang máy mới lại văng lỗi?
Code bị lỗi thụt lề trên máy mới vì cấu hình IDE mặc định ở mỗi máy tính (hoặc mỗi hệ điều hành Windows/Linux/Mac) quy định độ rộng của ký tự Tab (Tab size) là khác nhau. Trên máy cũ, IDE có thể cấu hình 1 Tab tương đương 4 spaces, nên bạn không nhận ra việc mình đang mix tab và space. Sang máy mới có cấu hình Tab là 8 spaces, bộ biên dịch phân giải sự chênh lệch khoảng trắng và ngay lập tức từ chối thực thi khối lệnh bị mâu thuẫn lề.
Kết luận
Việc sửa lỗi IndentationError: unindent does not match any outer indentation level không chỉ đòi hỏi bạn căn chỉnh lại khoảng trắng, mà còn là bài học về cách Python thực thi kỷ luật mã nguồn. Hãy chọn Cách 1 (hiển thị ký tự trắng và sửa tay) khi bạn cần học cách bắt đúng “bệnh” ở dòng nào, và ưu tiên Cách 2 (dùng tính năng Convert to Spaces của IDE) cho mọi dự án thực tế để đồng bộ hóa mã nguồn triệt để. Code sạch sẽ và thẳng hàng luôn là biểu hiện của một lập trình viên chỉn chu.
Các khóa học liên quan:
Một số sản phẩm từ Python:
Một số sách lập trình Python bạn hãy tham khảo